大规模语料与训练挑战
Deepseek-v3、Chat模型与R1推理模型的横空出世彻底点燃了全民AI的热情。
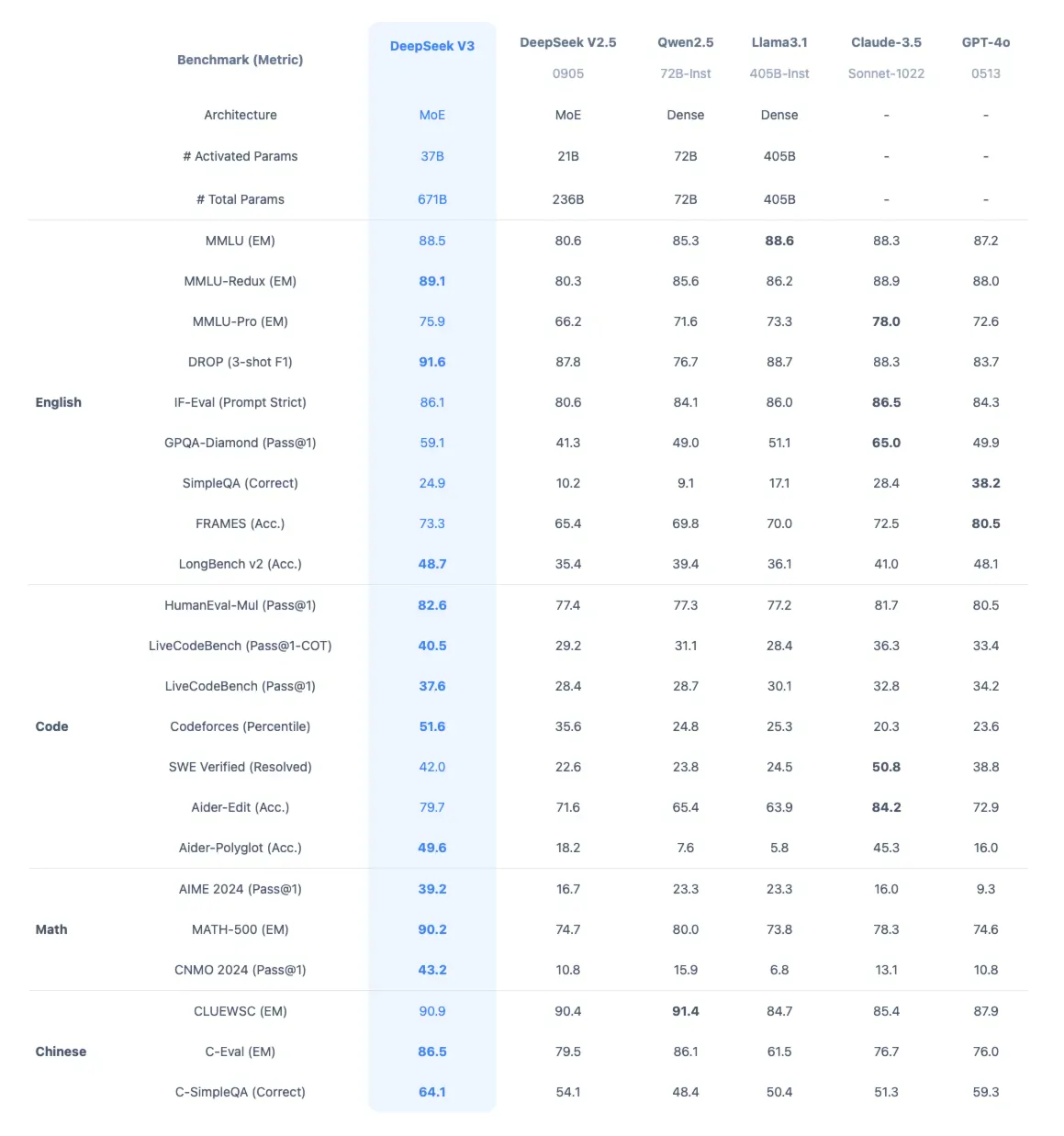
这一系列由中国AI科学家团队打造的开源大模型,凭借突破性的技术创新迅速在全球AI社区引起轰动。
Deepseek-v3以其强大的多语言理解能力、卓越的代码生成能力和惊人的数学推理能力成为业界新标杆;Chat模型则在对话流畅度和指令遵循方面表现出色;而R1推理模型更是在复杂推理任务上展现出接近人类的思考能力。从专业开发者到普通用户,从科技巨头到创业公司,无数人被这场AI技术飞跃所震撼。
AI应用的前景似乎一夜之间从科幻变为现实:智能助手能够理解复杂指令并完成创意写作,代码助手可以将想法转化为完整程序,数据分析师获得了强大的AI搭档,教育工作者发现了个性化教学的新可能...这股浪潮势不可挡,正以前所未有的速度重塑各行各业。
在这场技术变革中,企业和组织面临着一个关键问题:如何不仅仅是使用AI,而是真正掌握AI技术,使其为自身业务赋能?随着应用场景的深入,通用大模型的局限性逐渐显现,私有化训练和部署的需求日益迫切。然而,这条路并不平坦,其中蕴含着众多挑战与机遇。
引言:为什么需要了解大模型的训练挑战与私有化训练
随着大语言模型在各行各业的应用不断深入,越来越多的企业和组织开始考虑进行私有化训练或微调,而不仅仅依赖通用大模型。这主要出于以下几个关键原因:
- 数据安全与隐私保护:公共API模式下,敏感数据需要传输给第三方,存在潜在泄露风险;而私有化部署可确保数据留在组织内部
- 行业专业知识融入:通用模型对特定行业术语和知识的理解有限,针对性训练能显著提升专业领域表现
- 定制化需求与场景适配:不同组织有独特的业务流程和用户群体,定制训练能更好满足特定需求
- 成本与延迟控制:长期、高频使用场景下,私有部署可能比持续调用API更经济;同时消除网络延迟
- 摆脱依赖与技术自主:减少对特定AI提供商的依赖,增强技术自主性和可持续发展能力
然而,私有化训练大模型是一项极具挑战性的任务,需要面对数据、算力、技术等多方面的挑战。了解这些挑战,是任何希望驾驭大模型技术的团队必须跨越的第一道门槛。下面,我们将深入探讨大模型训练过程中的核心挑战,从语料数据准备到训练基础设施,再到算法优化等各个环节。
一、大语言模型的"食粮":语料数据
大语言模型(LLM)需要海量的文本数据进行训练,这些数据被称为"语料"。
1.1 语料数据的规模
现代大语言模型的训练数据规模是惊人的:
| 模型 | 训练数据规模 | 通俗比喻 |
|---|---|---|
| GPT-3 | 约45TB文本数据 | 相当于450万本《战争与和平》 |
| LLaMA | 超过1.4万亿个单词 | 如果按每分钟读200个单词计算,需要约13,000年才能读完 |
| Deepseek | 超过2万亿个标记 | 相当于人类历史上所有印刷书籍的几十倍 |
1.2 语料数据的来源
大型语言模型的训练数据主要来自以下几个渠道:
- 互联网网页:通过爬虫获取的各类网站内容
- 数字化书籍:电子书、数字图书馆
- 学术论文:科研文献、技术报告
- 代码仓库:开源代码平台如GitHub
- 百科全书:维基百科等结构化知识库
- 社交媒体:Twitter、Reddit等公开讨论
- 新闻文章:各类新闻媒体内容
1.3 语料数据质量的重要性
并非所有数据都适合训练模型,高质量语料的特点包括:
- 准确性:信息正确无误
- 多样性:涵盖不同主题、风格和观点
- 时效性:包含较新的信息
- 无偏见:不含有害或极端内容
- 结构良好:格式一致,易于处理
二、数据处理的挑战
原始语料不能直接用于训练,需要经过一系列处理。
2.1 数据收集与清洗
- 爬虫挑战:如何高效爬取并符合网站规则
- 去重处理:删除重复内容(网页镜像、多次转载)
- 质量过滤:
- 去除垃圾内容(广告、垃圾邮件格式)
- 筛选掉低质量文本(语法错误多、无意义内容)
- 剔除有害内容(偏见、仇恨言论、不当信息)
2.2 文本预处理
将原始文本转换为模型可处理的格式:
- 分词:将文本切分为标记(tokens)
- 规范化:统一文本格式(如大小写、标点符号处理)
- 特殊标记添加:添加表示文本开始、结束等的特殊标记
- 序列划分:将长文本划分为适当长度的序列
2.3 数据多样性与平衡
确保训练数据的多样性和平衡性:
- 语言分布:各种语言的合理比例(英语、中文、其他语言)
- 领域平衡:科技、文学、新闻、社交媒体等不同领域
- 时间分布:不同时期的内容,保证历史和现代知识
- 格式多样性:对话、叙述、问答、代码等不同格式
三、训练基础设施挑战
训练大型语言模型需要巨大的计算资源。
3.1 硬件需求
现代大语言模型的训练需要:
| 资源类型 | 数量级 | 通俗比喻 |
|---|---|---|
| GPU/TPU | 数百至数千个 | 相当于几百台高端游戏电脑的算力 |
| 内存 | 数TB至数PB | 相当于数万部高清电影的存储空间 |
| 网络带宽 | 数百Gbps | 能在几秒内下载一部4K电影 |
| 电力消耗 | 数兆瓦 | 足够供应一个小型社区的用电需求 |
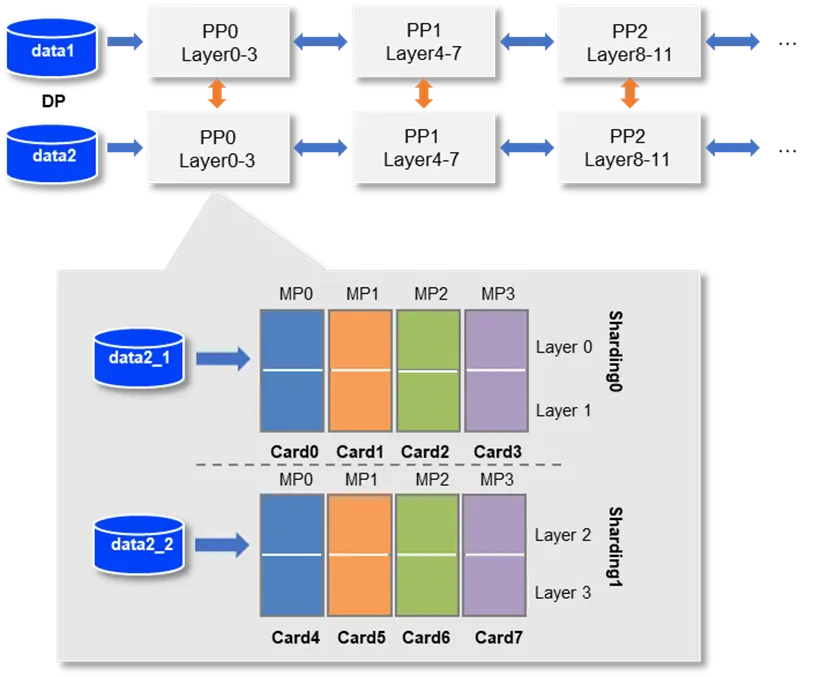
3.2 分布式训练
由于单个计算设备无法完成训练,需要分布式系统:
- 模型并行:将模型分割到多个设备上
- 数据并行:同一模型在不同设备上处理不同数据
- 流水线并行:将模型层次分布到不同设备,形成处理流水线
- 混合并行策略:综合上述方法优化训练效率
飞桨分布式训练示意:
3.3 训练稳定性
长时间训练过程中的挑战:
- 硬件故障:单个设备故障不应导致整体训练失败
- 梯度爆炸/消失:数值稳定性问题需要特殊处理
- 检查点保存:定期保存训练状态以便从故障恢复
- 分布式同步:确保多设备之间的数据同步和一致性
四、算法和优化挑战
除了硬件和数据挑战,算法层面也存在诸多难题。
4.1 超参数调优
训练过程中的关键参数需要精心设置:
- 学习率:过大导致不收敛,过小训练过慢
- 批次大小:影响内存使用和训练稳定性
- 优化器选择:不同优化器对训练效果影响显著
- 权重衰减:防止过拟合的重要参数
4.2 训练效率优化
提高训练效率的常见策略:
- 混合精度训练:结合FP16/BF16和FP32提高速度和节省内存
- 梯度累积:处理超大批次而不消耗额外内存
- 激活值重计算:牺牲计算换取内存
- 优化器内存使用:如使用8位优化器、ZeRO优化器等
- 高效注意力算法:减少注意力机制的计算复杂度
4.3 评估与迭代
训练过程中的持续评估:
- 验证集设计:确保代表性和多样性
- 指标选择:困惑度(Perplexity)、准确率等多种指标结合
- 人工评估:定期进行人工质量评估
- 早期问题检测:及时发现训练异常并调整
- 持续改进:基于评估结果迭代优化训练策略
五、训练后的挑战
模型训练完成后,仍面临多项挑战:
5.1 模型压缩
原始训练模型通常过大,需要压缩以便部署:
- 量化:将32位浮点参数降为8位或更低,大幅减小模型体积
- 蒸馏:训练小模型模仿大模型行为
- 剪枝:移除不重要的连接或神经元
- 低秩分解:使用矩阵分解减少参数数量
5.2 评估与安全
确保模型行为符合预期:
- 综合能力评估:测试多种语言能力和任务表现
- 偏见检测:检查模型是否存在偏见或歧视性输出
- 有害内容生成风险:评估模型生成有害内容的可能性
- 事实准确性:检验模型输出信息的准确程度
- 鲁棒性测试:对抗样本测试和边界情况测试
六、小结
大语言模型的训练是一项极其复杂的系统工程,涉及数据、硬件、算法、评估等多个方面的挑战。了解这些挑战不仅有助于理解当前模型的局限性,也能帮助我们更好地规划和实施模型训练项目。
随着技术的发展,我们看到了许多应对这些挑战的创新方法:
- 更高效的训练算法
- 更经济的硬件利用策略
- 更智能的数据筛选和处理方法
- 更全面的评估和优化体系
思考问题:如果你要训练一个专门用于特定领域(如医疗或法律)的语言模型,你认为会面临哪些独特的数据和训练挑战?